Deploying an HuggingFace embedding model to Amazon SageMaker and consuming it with Llama-Index
TL;DR: In this blog post, you will learn how to choose an embedding model from HuggingFace and use it with Amazon SageMaker to generate embeddings. I will show you how to use SageMaker real-time endpoints, SageMaker Batch Transform, and how SageMaker integrates with Llama-Index.

What is an Embedding Model?
Embedding models are a type of machine learning model that converts input data, such as text or images, into numerical representations called embeddings. These embeddings capture the semantic meaning or context of the input data in a continuous vector space. By encoding data into embeddings, complex relationships and similarities between different data points can be captured and used for various tasks like similarity search, recommendation systems, and natural language processing. Embeddings are key when implementing architecture like Retrieval Augmented Generation (RAG) in the world of Large Language Models (LLM).
In other words, as humans we know that the word “king” is semantically closer to the word “queen” than it is to the word “zebra”, just like we know that “zebra” is closer to “lion” than “queen”. Embeddings are a way to represent this “semantic relationship” via numbers, which computers can understand. Similarity can be computed via metrics like cosine similarity, Euclidean distance, Manhattan distance, Kullback-Leibler Divergence, etc.
Where to find embedding models?
One of the best resources to find embedding models is the Hugging Face Hub, in particular I like to choose from the Massive Text Embedding Benchmark (MTEB) Leaderboard.
The MTEB Leaderboard contains a ranked list of model embeddings, ranked by overall performance across a series of benchmarks across multiple datasets and multiple tasks. Some important parameters to look at when choosing the embedding models are:
- Size of the model — bigger models require more resources to be loaded into memory, as well as might require GPU in order to obtain predictions fast enough to be usable
- Max tokens — AKA context window, how many tokens the model can accept as input; higher values are better, however this means bigger compute and memory requirements;
- Embedding Dimension — AKA how many floating point numbers will be produced by the model, how long the embedding will be; higher is better for increased nuances of the language but introduces additional computational complexity;
- Support for multiple languages (unless you only work with English documents)
How to deploy to Amazon SageMaker?
Even before deploying our model to Amazon SageMaker, we’ll need to consider the use case that we’re trying to solve, and what kind of inference we will require. Amazon SageMaker supports four deployment types:
- real-time endpoint: an instance that runs 24/7 and is paid by the hour; ideal for production workloads that require real-time predictions
- batch transform: an ephemeral task that spins up when the API is called, performs prediction on a dataset uploaded to Amazon S3, then stops; ideal when you have big datasets, for initial ingestion of vectors in a database, or when you are ok waiting for execution to be complete
- asynchronous endpoint: a solution in between real-time endpoint and batch transform, being a real-time endpoint that scales down to zero when no requests are in queue and loads inputs from S3; large files to be transformed while still having the flexibility to quickly receive an output once the endpoint is up, as well as in general cost optimization, are great use cases for asynchronous endpoints
- serverless endpoint: a true serverless implementation of a real-time endpoint, loading the model only when needed, generating inferences, then shutting down the endpoint; great for smaller models in production (low cold start) and cost optimization purposes, ideal during the development phase
In this blog, I will detail how to implement the first two approaches. Reach out if you’re interested in deploying to asynchronous endpoints, and I might write a new post on the topic ☺️️
Note that the below code snippets can be run anywhere — it doesn’t have to be in Amazon SageMaker Studio!
Step 1 — Configure Amazon SageMaker
#### SAGEMAKER SETUP ####
import sagemaker
import boto3
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='[REPLACE WITH YOUR EXECUTION ROLE NAME')['Role']['Arn']
session = sagemaker.Session()
default_bucket = session.default_bucket()The first step is to set up the permissions for SageMaker. If you’re running this code in a SageMaker Studio Notebook, the get_execution_role() API will automatically load the SageMaker execution role assigned to your user. Otherwise, you will need to retrieve the role from AWS IAM. You can provide it manually, or retrieve it dynamically, like in this code snippet.
Step 2 — Load the model from the Hub
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'intfloat/multilingual-e5-large-instruct', # model_id from hf.co/models
'HF_TASK':'feature-extraction', # NLP task you want to use for predictions
# 'SM_NUM_GPUS': '1',
}Here, we’ll configure everything that is needed by the model in the HF Hub to be loaded with SageMaker. In particular, you’ll need at least two parameters:
HF_MODEL_ID— fill this with the repository and model name from the HF Hub, in my caseintfloat/multilingual-e5-largeHF_TASK— important parameter to tell the Hugging Face container that you’re trying to load an embedding model, and should therefore use this to generate embeddings, so let’s set this tofeature-extraction
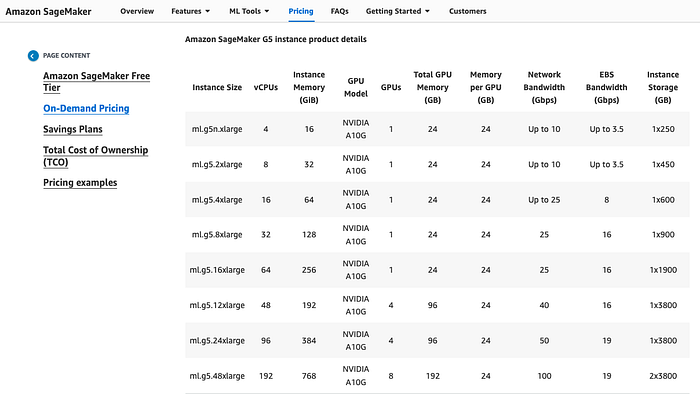
Optionally, configure the SM_NUM_GPUS, which tells the container how many GPUs are there in the instance, so that it can use them all. For this model, I don’t actually need GPUs, so I’m not setting any parameter — we’ll configure the instance in the next step. To figure out how many GPUs your instance has, head over to the SageMaker Pricing page and check out the instance details towards the middle of the page.
Step 3 — Configure the HF container
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
py_version='py310',
transformers_version="4.37.0", # transformers version used
pytorch_version="2.1.0", # pytorch version used
)Until the Text-Embedding-Inference container from Hugging Face officially comes to Amazon SageMaker, we need to use the generic Hugging Face Transformers container to load our model. To do that, we will need to specify, aside from the previous model configuration, the Python version, the Transformers library version, and the PyTorch version.
Trick: there is no way you can learn by heart the combination of these three parameters. I always refer to the list of available images for Hugging Face Inference containers from the official AWS Deep Learning Containers repository.
Step 4 — Deploy
We’re now ready to deploy! Let’s start with real-time deployment:
embedding_predictor = huggingface_model.deploy(
endpoint_name=sagemaker.utils.name_from_base("intfloat-multilingual-e5-large-instruct"),
initial_instance_count=1,
instance_type="ml.c5.2xlarge"
)As you can see, for this relatively small but powerful model I chose a CPU instance, the ml.c5.2xlarge. This will be more than enough to load the model in memory, and significantly cheaper than a GPU instance, although a bit slower in generating inference:
embedding_predictor.predict({"inputs": [
"In un giorno di pioggia, Andrea e Giuliano incontrano Licia per caso.",
"Poi Mirko, finita la pioggia, si incontra e si scontra con Licia."
]
})Since the instance is not very powerful, this transformation can take up to 10 seconds to be generated, for two relatively short sentences! When you look at the operational metrics in the SageMaker endpoint page, you can see that the limiting factor here is memory:

The nice things about Amazon SageMaker and Hugging Face integration, is that you can very easily change instance, with very few code changes:
#### EMBEDDING MODEL DEPLOYMENT ####
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'intfloat/multilingual-e5-large-instruct', # model_id from hf.co/models
'HF_TASK':'feature-extraction' # NLP task you want to use for predictions
'SM_NUM_GPUS': '1',
}
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
py_version='py310',
transformers_version="4.37.0", # transformers version used
pytorch_version="2.1.0", # pytorch version used
)
embedding_predictor = huggingface_model.deploy(
endpoint_name=sagemaker.utils.name_from_base("intfloat-multilingual-e5-large-instruct"),
initial_instance_count=1,
instance_type="ml.g5.2xlarge"
)You can now test and see that predictions are generated much faster 🚀️ For comparison, the predictions now take 1~2 seconds on GPU instead.
The same configuration can be used to use Batch Transform to generate predictions in batches. Batch Transform requires a file to be in Amazon S3, with a header “inputs”, and the lines to embed. For example, if you want to obtain the embedding of the song “Here comes the sun” by The Beatles, your JSONLines file should look like this:
{"id":1,"text_inputs":"Here comes the sun (Doo-d-doo-doo)"}
{"id":2,"text_inputs":"Here comes the sun"}
{"id":3,"text_inputs":"And I say, 'It's alright'"}Starting from the same huggingface_model class from before, we can now define a transformer, which will allow us to execute a Batch Transform job:
transformer = huggingface_model.transformer(
instance_count=1,
instance_type="ml.m5.4xlarge",
assemble_with="Line",
max_payload=1
)
transformer.transform(
data=s3_path,
split_type="Line",
content_type="application/jsonlines",
job_name=sagemaker.utils.name_from_base("intfloat-multilingual-e5-large-instruct")
)This is going to take some time — a bit under 10 minutes. You will be able to check the outputs stored in Amazon S3 by copying the files in the output path:
!aws s3 sync $transformer.output_path ./embedding-outputs/
!ls -la ./embedding-outputs/The output format is:
{"id":1, "embedding":[0.025507507845759392, 0.009654928930103779, -0.01139055471867323, ………]}
{"id":2, "embedding":[-0.018594933673739433, -0.011756304651498795, -0.006888044998049736,…..]}
[...]Using embedding models in Amazon SageMaker with Llama-Index

Not every single time you will have a very nice text file split line by line. Often, you have just a big document that you would like to embed, so that you can then perform searches on it. By not doing a smart chunking/splitting of the text, we lose semantic relations between words and sentences inside the book.
Let’s solve this by using Llama-index. Llama-index has introduced support for embedding models deployed on SageMaker endpoints in January 2024.
First, install llama-index (make sure you’re running llama-index>=0.10.6) :
pip install llama-indexYou can manually query the SageMaker endpoint from llama-index:
from llama_index.embeddings.sagemaker_endpoint import SageMakerEmbedding
embedding_model = SageMakerEmbedding(
endpoint_name=embedding_predictor.endpoint_name
)# Get one embedding
embedding = embedding_model.get_text_embedding(
"An Amazon SageMaker endpoint is a fully managed resource that enables the deployment of machine learning models, specifically LLM (Large Language Models), for making predictions on new data."
)
print(embedding)
# Get embeddings in batch
embeddings = embedding_model.get_text_embedding_batch(
[
"An Amazon SageMaker endpoint is a fully managed resource that enables the deployment of machine learning models",
"Sagemaker is integrated with llamaIndex",
]
)
print(embeddings)Or you can set it so that it’s the default embedding model for your pipelines:
from llama_index.core import Settings
# Configure Llama-index so that the default embedding model is our endpoint
Settings.embed_model = embedding_modelThen you can use this embedding model in your RAG pipelines.
For this example, I will be using the book “Le avventure di Pinocchio: Storia di un burattino” by C. Collodi, available for free on Project Gutenberg.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.node_parser import SentenceSplitter
# Step 1 - Load Data
documents = SimpleDirectoryReader("data").load_data()
# Step 2 - Index Data
index = VectorStoreIndex.from_documents(
documents,
transformations=[SentenceSplitter(chunk_size=250, chunk_overlap=50)]) # Max tokens size is 512 for this model
)Once the index has been built, you can now query it, and use your favorite LLM to generate an answer:
# I have previously deployed an LLM on an endpoint
# I will use SageMaker endpoint for this step as well!
from llama_index.llms.sagemaker_endpoint import SageMakerLLM
Settings.llm = SageMakerLLM(endpoint_name=llm_predictor.endpoint_name)
# Step 3- Query
query_engine = index.as_query_engine()
response = query_engine.query("Come si chiama il padre di Pinocchio?")
print(response)Congratulations on making it this far! In this blog post, you’ve learned:
- what are embeddings
- how to deploy them on Amazon SageMaker
- how to use SageMaker endpoints in Llama-index
Check out the other blog posts I’ve written here on Medium, you will definitely find something to your liking! See you on the next Medium post!








